The WHAMVox Dataset
WHAMVox contains two subsets, each with 1940 files:
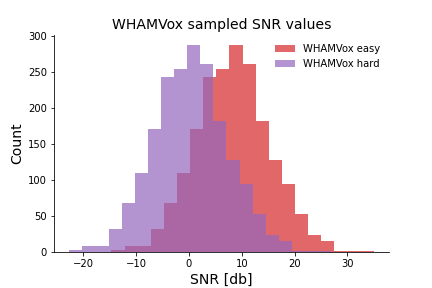
- WHAMVox easy covering the SNR range -12dB to 27dB SNR.
- WHAMVox hard covering the SNR range -20dB to 20dB SNR.
Each sound file consists of mixed speech from the VoxCeleb2 [1] and noise from the WHAM! [2] test datasets. Corresponding clean speech files are included for each example.
WHAMVox easy can be downloaded here.
WHAMVox hard can be downloaded here.
Metadata containing the ids and paths of the speech and noise files for each example as well as the URL to the original speech videos can be found here. A zipfile containing the URL of each YouTube video from which each speech sample was taken along with timestamps for utterances can be downloaded here. The frame number assumes that the video is saved at 25fps.
For more details about how the files were selected, please see the ipython notebook analyses.ipnb.
Dataset Statistics
Code
Code and instructions to recreate or modify the test datasets is available on our corresponding Github page. Please follow the instructions in the README.
Citation
WHAMVox was compiled by Audatic. If you make use of this dataset please cite our corresponding paper:
Restoring speech intelligibility for hearing aid users with deep learning
Diehl, P.U., Singer, Y., Zilly, H., Schönfeld, U., Meyer-Rachner, P., Berry, M., Sprekeler, H., Sprengel, E., Pudszuhn, A. & Hofmann, V.M. Restoring speech intelligibility for hearing aid users with deep learning. Sci Rep 13, 2719 (2023).
https://doi.org/10.1038/s41598-023-29871-8
References
[1] J. S. Chung, A. Nagrani, A. Zisserman
VoxCeleb2: Deep Speaker Recognition
INTERSPEECH, 2018.
[2] Gordon Wichern, Joe Antognini, Michael Flynn, Licheng Richard Zhu, Emmett McQuinn, Dwight Crow, Ethan Manilow, Jonathan Le Roux
WHAM!: Extending Speech Separation to Noisy Environments
INTERSPEECH, 2019.
License
Creative Commons License This work is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License.